借助 MCP 进行代码执行:构建更高效的智能体
直接调用工具会为每条定义与每个结果消耗上下文。通过编写代码来调用工具,智能体的扩展性更好。下面介绍在 MCP 中它是如何实现的。
Model Context Protocol(MCP) 是一个将 AI 智能体连接到外部系统的开放标准。传统上,把智能体接入工具与数据往往需要为每一对组合做一次定制集成,这会造成割裂与重复劳动,难以扩展真正互联的系统。MCP 提供了通用协议——开发者在智能体里只需实现一次 MCP,就能解锁整个集成生态。
自 2024 年 11 月发布 MCP 以来,其采用速度非常快:社区已构建了数千个 MCP 服务器,SDK 覆盖所有主流编程语言,业界也将 MCP 作为连接智能体与工具和数据的事实标准。
如今,开发者经常构建能通过数十个 MCP 服务器访问数百甚至上千工具的智能体。然而,随着连接的工具越来越多,在启动时加载全部工具定义并把中间结果通过上下文窗口传递,会拖慢智能体并增加成本。
本文将探讨代码执行如何让智能体更高效地与 MCP 服务器交互:在处理更多工具的同时使用更少的 token。
工具导致的过多 token 消耗会降低智能体效率
随着 MCP 使用规模扩大,有两种常见模式会增加智能体的成本和时延:
- 工具定义让上下文窗口超载;
- 中间工具结果消耗额外 token。
1. 工具定义让上下文窗口超载
大多数 MCP 客户端会在启动时把所有工具定义直接加载进上下文,并以直接工具调用的语法暴露给模型。这些工具定义大致如下:
gdrive.getDocument
Description: 从 Google Drive 获取一个文档
Parameters:
documentId (必填, string): 要检索的文档 ID
fields (可选, string): 要返回的特定字段
Returns: 带有标题、正文内容、元数据、权限等的 Document 对象
复制
salesforce.updateRecord
Description: 在 Salesforce 中更新一条记录
Parameters:
objectType (必填, string): Salesforce 对象类型(如 Lead、Contact、Account 等)
recordId (必填, string): 要更新的记录 ID
data (必填, object): 需要更新的字段及其新值
Returns: 返回带确认信息的已更新记录对象
复制
工具描述会占用更多上下文窗口空间,从而增加响应时间和成本。在智能体连接上千工具的场景下,它们在理解请求之前可能就需要处理数十万 token。
2. 中间工具结果会消耗额外 token
大多数 MCP 客户端允许模型直接调用 MCP 工具。比如,你可能会让智能体执行:“从 Google Drive 下载我的会议纪要,并把它附加到 Salesforce 线索上。”
模型会发出类似这样的调用:
TOOL CALL: gdrive.getDocument(documentId: "abc123")
→ returns "Discussed Q4 goals...\n[full transcript text]"
(载入模型上下文)
TOOL CALL: salesforce.updateRecord(
objectType: "SalesMeeting",
recordId: "00Q5f000001abcXYZ",
data: { "Notes": "Discussed Q4 goals...\n[full transcript text written out]" }
)
(模型需要再次把整段纪要写入到上下文中)
复制
每一个中间结果都必须经过模型。在这个示例中,完整的通话纪要会在流程中经过两次。对于一场 2 小时的销售会议,这可能意味着额外处理约 50,000 个 token。更大的文档甚至可能超过上下文窗口限制,从而使工作流失败。
对于大型文档或复杂数据结构,在工具调用之间复制数据时,模型更容易出错。
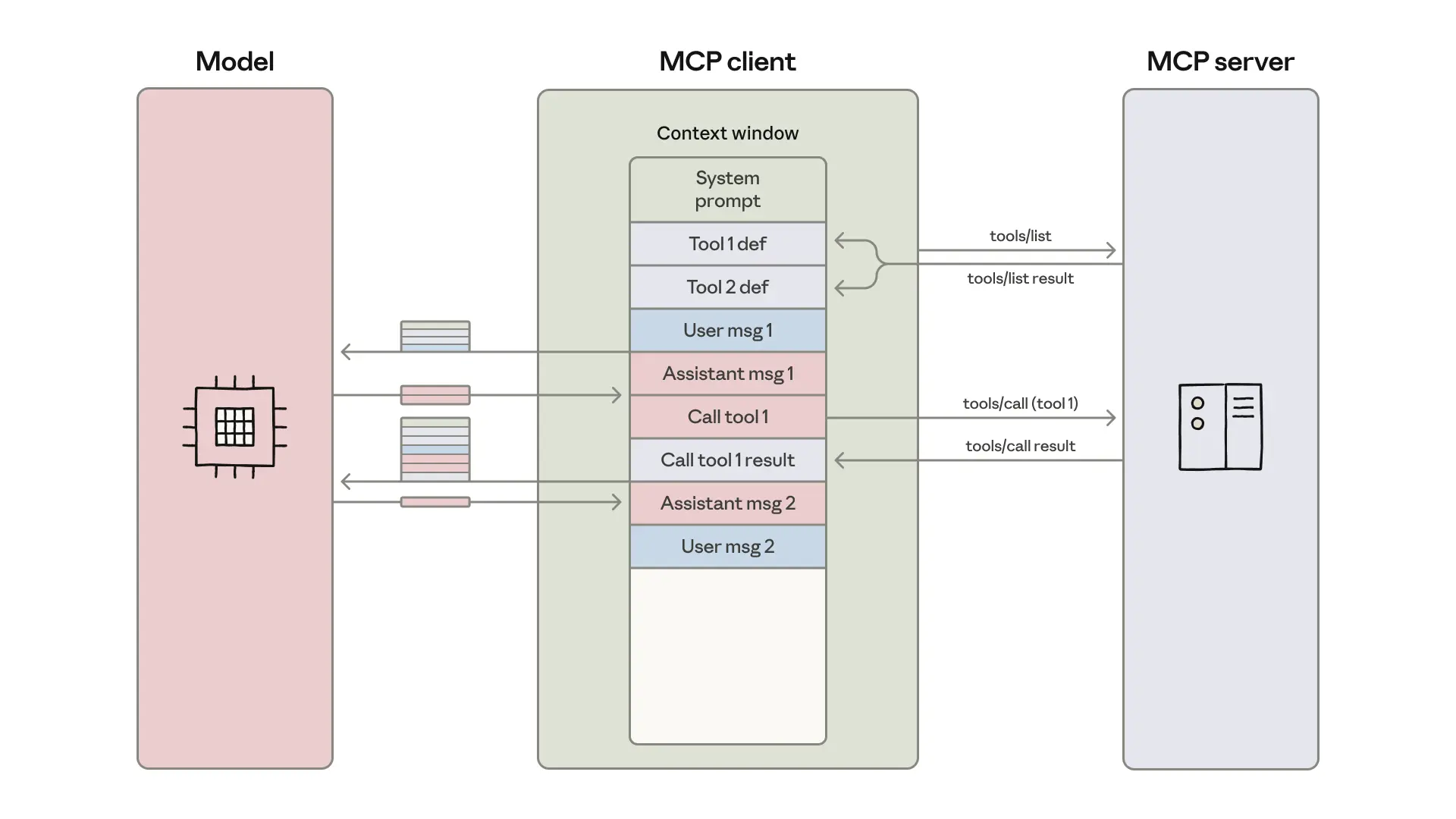
使用 MCP 的代码执行可提升上下文效率
随着面向智能体的代码执行环境越来越常见,一种解决方案是把 MCP 服务器呈现为代码 API,而不是直接工具调用。这样,智能体就可以通过编写代码与 MCP 服务器交互。这种方法同时解决了两点:智能体只加载所需工具,并能在把结果返回给模型之前在执行环境中过滤与处理数据。
实现方式有很多。一个做法是从已连接的 MCP 服务器生成一棵包含所有可用工具的文件树。下面是一个使用 TypeScript 的实现:
servers
├── google-drive
│ ├── getDocument.ts
│ ├── ... (other tools)
│ └── index.ts
├── salesforce
│ ├── updateRecord.ts
│ ├── ... (other tools)
│ └── index.ts
└── ... (other servers)
复制
随后,每个工具对应到一个文件,类似这样:
// ./servers/google-drive/getDocument.ts
import { callMCPTool } from "../../../client.js";
interface GetDocumentInput {
documentId: string;
}
interface GetDocumentResponse {
content: string;
}
/* 从 Google Drive 读取一个文档 */
export async function getDocument(input: GetDocumentInput): Promise<GetDocumentResponse> {
return callMCPTool<GetDocumentResponse>('google_drive__get_document', input);
}
复制
上面从 Google Drive 到 Salesforce 的示例可以写成代码:
// 从 Google Docs 读取会议纪要,并添加到 Salesforce 线索
import * as gdrive from './servers/google-drive';
import * as salesforce from './servers/salesforce';
const transcript = (await gdrive.getDocument({ documentId: 'abc123' })).content;
await salesforce.updateRecord({
objectType: 'SalesMeeting',
recordId: '00Q5f000001abcXYZ',
data: { Notes: transcript }
});
复制
智能体可以通过探索文件系统来发现工具:列出 ./servers/ 目录以找到可用的服务器(如 google-drive 和 salesforce),然后读取所需的具体工具文件(如 getDocument.ts 和 updateRecord.ts)来理解每个工具的接口。这样,智能体只需为当前任务加载必要的定义。由此,token 使用量可以从 150,000 降到 2,000——节省了 98.7% 的时间与成本。
Cloudflare 发布了类似的结论,把结合 MCP 的代码执行称为“Code Mode”。核心洞见相同:LLM 擅长写代码,开发者应该利用这一优势来构建更高效与 MCP 服务器交互的智能体。
代码执行与 MCP 的收益
结合 MCP 的代码执行让智能体能更高效地使用上下文:按需加载工具、在数据进入模型前进行过滤与转换、并把复杂逻辑一次性在执行环境中完成。这种方法在安全与状态管理上也有益处。
渐进式披露
模型非常擅长在文件系统中导航。把工具以代码形式放在文件系统上,可以让模型按需读取工具定义,而不是一开始就把所有定义都读入。
或者,也可以在服务器上提供一个 search_tools 工具来查找相关定义。例如,在上面的 Salesforce(假想)服务器中,智能体可以搜索“salesforce”,并只加载当前任务所需的工具。给 search_tools 工具加入“细节级别”参数,让智能体选择所需的细节层次(例如仅名称、名称与描述、或包含 schema 的完整定义),也有助于节省上下文并高效定位工具。
上下文高效的工具结果
在处理大规模数据集时,智能体可以先在代码里对结果进行筛选与转换,再返回给模型。考虑拉取一个包含 10,000 行的数据表:
// 无代码执行——所有行都经由上下文
TOOL CALL: gdrive.getSheet(sheetId: 'abc123')
→ 返回 10,000 行,需要在上下文中手动筛选
// 使用代码执行——在执行环境中过滤
const allRows = await gdrive.getSheet({ sheetId: 'abc123' });
const pendingOrders = allRows.filter(row =>
row["Status"] === 'pending'
);
console.log(`Found ${pendingOrders.length} pending orders`);
console.log(pendingOrders.slice(0, 5)); // 仅打印前 5 行用于审阅
复制
智能体看到的是 5 行,而不是 10,000 行。类似的模式也适用于聚合、跨多数据源的关联,或抽取特定字段——这一切都不会让上下文窗口臃肿。
更强大且上下文高效的控制流
循环、条件与错误处理可以用熟悉的代码模式完成,而无需把多个工具调用串起来。比如,如果你需要在 Slack 中等待一次部署完成的通知,智能体可以这样写:
let found = false;
while (!found) {
const messages = await slack.getChannelHistory({ channel: 'C123456' });
found = messages.some(m => m.text.includes('deployment complete'));
if (!found) await new Promise(r => setTimeout(r, 5000));
}
console.log('Deployment notification received');
复制
这种方式比在智能体循环中交替进行 MCP 工具调用与 sleep 命令更高效。
此外,把需要执行的条件分支写成代码还能降低“首 token 时间”延迟:无需等待模型去判断 if 语句,由代码执行环境直接完成即可。
隐私保护操作
当智能体通过代码执行结合 MCP 时,中间结果默认留在执行环境内。也就是说,智能体只会看到你明确记录(log)或返回的内容——你不想与模型分享的数据可以在整个流程中穿过,但永远不会进入模型的上下文。
对于更敏感的工作负载,代理运行器(harness)还可以自动对敏感数据进行令牌化。例如,假设你需要把电子表格中的客户联系方式导入到 Salesforce。智能体可以这样写:
const sheet = await gdrive.getSheet({ sheetId: 'abc123' });
for (const row of sheet.rows) {
await salesforce.updateRecord({
objectType: 'Lead',
recordId: row.salesforceId,
data: {
Email: row.email,
Phone: row.phone,
Name: row.name
}
});
}
console.log(`Updated ${sheet.rows.length} leads`);
复制
MCP 客户端会在数据进入模型之前拦截并将 PII 令牌化:
// 如果智能体把 sheet.rows 打印出来,它会看到:
[
{ salesforceId: '00Q...', email: '[EMAIL_1]', phone: '[PHONE_1]', name: '[NAME_1]' },
{ salesforceId: '00Q...', email: '[EMAIL_2]', phone: '[PHONE_2]', name: '[NAME_2]' },
...
]
复制
随后,当这些数据在另一次 MCP 工具调用中被使用时,客户端会通过查找把它们“去令牌化”。真实的邮箱、电话和姓名会从 Google Sheets 流向 Salesforce,但不会经过模型。这能防止智能体意外记录或处理敏感数据。你也可以借此定义确定性的安全规则,明确数据可以从哪里流向哪里。
状态持久化与技能
具有文件系统访问能力的代码执行允许智能体在多次操作之间维护状态。智能体可以把中间结果写入文件,从而支持恢复工作与跟踪进度:
const leads = await salesforce.query({
query: 'SELECT Id, Email FROM Lead LIMIT 1000'
});
const csvData = leads.map(l => `${l.Id},${l.Email}`).join('\n');
await fs.writeFile('./workspace/leads.csv', csvData);
// 后续的执行可以在此基础上继续
const saved = await fs.readFile('./workspace/leads.csv', 'utf-8');
复制
智能体也可以把自己写出的代码持久化为可复用函数。一旦某个任务有了可用实现,智能体可以把它保存下来,供未来复用:
// 位于 ./skills/save-sheet-as-csv.ts
import * as gdrive from './servers/google-drive';
export async function saveSheetAsCsv(sheetId: string) {
const data = await gdrive.getSheet({ sheetId });
const csv = data.map(row => row.join(',')).join('\n');
await fs.writeFile(`./workspace/sheet-${sheetId}.csv`, csv);
return `./workspace/sheet-${sheetId}.csv`;
}
// 在后续任意一次执行中:
import { saveSheetAsCsv } from './skills/save-sheet-as-csv';
const csvPath = await saveSheetAsCsv('abc123');
复制
这与 Skills 的概念密切相关:为模型准备的、可复用的说明、脚本与资源文件夹,帮助其在专项任务上表现更好。给这些保存的函数补充一份 SKILL.md,可以把它们组织成结构化技能,供模型引用与调用。随着时间推移,你的智能体将积累出一套更高层次的工具箱,逐步演化出让它更高效工作的脚手架。
需要注意的是,代码执行也会引入自身的复杂性。运行由智能体生成的代码,需要安全的执行环境以及合适的沙盒、资源限制与监控。这些基础设施要求会带来运维开销与安全考量,而直接工具调用则不需要。应当在代码执行带来的收益(更低的 token 成本、更低的时延、更好的工具组合能力)与这些实现成本之间权衡。
总结
MCP 为智能体连接众多工具与系统提供了基础协议。然而,一旦连接的服务器过多,工具定义与结果就可能消耗过量 token,降低智能体效率。
尽管这里的许多问题看起来很新——上下文管理、工具组合、状态持久化——但在软件工程中都有成熟的解决方案。代码执行把这些既有模式应用到智能体中,让它们用熟悉的编程构造更高效地与 MCP 服务器交互。如果你采用了这种方法,欢迎把你的经验分享给 MCP 社区。
致谢
本文由 Adam Jones 和 Conor Kelly 撰写。感谢 Jeremy Fox、Jerome Swannack、Stuart Ritchie、Molly Vorwerck、Matt Samuels 和 Maggie Vo 对本文草稿提出的反馈。
订阅开发者新闻简报
产品更新、操作指南、社区亮点等,每月一次直达你的收件箱。
如果你希望收到我们的每月开发者新闻简报,请留下邮箱地址。你可以随时取消订阅。