无标题
title: "Harness design for long-running application development" translated_title: "面向长时运行应用开发的 Harness 设计" date: 2026-03-24 url: https://www.anthropic.com/engineering/harness-design-long-running-apps author: Anthropic source: anthropic.com fetched: 2026-03-25 12:53:01 translated: "2026-03-25 08:53:04"
Harness 设计是代理式编程前沿性能的关键。以下是我们如何让 Claude 在前端设计和长时间自主软件工程中更进一步。
作者:Prithvi Rajasekaran,Anthropic Labs 团队成员。
在过去几个月里,我一直在处理两个相互关联的问题:让 Claude 产出高质量的前端设计,以及让它在无人干预的情况下构建完整应用。这项工作起源于我们此前在 frontend design skill 和 long-running coding agent harness 上的探索。当时,我和同事们通过提示工程与 harness 设计,让 Claude 的表现显著超过基线——但这两条路线最终都碰到了天花板。
为了突破这一点,我开始寻找能够同时适用于两个截然不同领域的新型 AI 工程方法:一个由主观审美定义,另一个由可验证的正确性与可用性定义。受 生成对抗网络(GAN)的启发,我设计了一种包含 generator(生成器)与 evaluator(评估器)代理的多代理结构。要构建一个既能稳定打分、又“有品味”的评估器,首先就需要建立一套标准,把“这个设计好吗?”这类主观判断转化为具体、可评分的条目。
随后,我将这些技术应用到长时间自主编程中,并继承了我们早期 harness 工作中的两条经验:把构建过程拆解成可处理的小块,以及使用结构化工件在不同会话之间传递上下文。最终结果是一个由 planner、generator 和 evaluator 组成的三代理架构,它能在持续数小时的自主编程会话中产出丰富的全栈应用。
为什么朴素实现会失效
我们此前已经展示过,harness 设计会显著影响长时间代理式编程的效果。在早先的一项实验中,我们使用一个 initializer 代理将产品规格拆解为任务列表,再由一个 coding 代理逐项实现功能,并在会话之间交接工件以传递上下文。更广泛的开发者社区也逐渐得出了类似结论,比如 “Ralph Wiggum” 方法就通过 hooks 或脚本让代理持续处于迭代循环中。
但有些问题依然顽固存在。对于更复杂的任务,代理仍然会随着时间推移逐渐偏离轨道。在拆解这个问题时,我们观察到代理在执行这类任务时有两种常见失效模式。
第一种是,随着上下文窗口逐渐被填满,模型在长任务上往往会失去连贯性(参见我们关于 context engineering 的文章)。有些模型还会表现出“上下文焦虑(context anxiety)”:当它们接近自己认为的上下文上限时,就会开始过早收尾。上下文重置——即彻底清空上下文窗口并启动一个全新的代理,同时配合结构化交接,把前一个代理的状态和下一步计划传递过去——可以同时解决这两个问题。
这与压缩(compaction)不同。压缩是将对话早期部分原地总结,让同一个代理基于缩短后的历史继续工作。虽然压缩保留了连续性,但它并没有给代理一个真正的“干净起点”,因此上下文焦虑仍可能持续存在。重置则提供了一个全新的起点,代价是交接工件必须携带足够的状态,才能让下一个代理顺利接手工作。在我们早期测试中,Claude Sonnet 4.5 的上下文焦虑表现得足够明显,以至于仅靠压缩不足以支持强劲的长任务表现,因此上下文重置成为 harness 设计中的关键组成部分。这解决了核心问题,但也为每次 harness 运行增加了编排复杂度、token 开销和延迟。
第二个问题——我们此前尚未处理过——是自我评估。当代理被要求评估自己产出的工作时,它们往往会信心十足地称赞自己的成果——即使在人类观察者看来,质量明显平庸。这个问题在设计这类主观任务上尤其突出,因为这里不存在类似可验证软件测试那样的二元检查。一个布局究竟显得精致还是普通,本质上是判断问题,而代理在给自己的作品打分时会稳定地偏向正面。
不过,即便是在那些有可验证结果的任务上,代理有时也会表现出糟糕的判断力,从而阻碍任务完成。将“执行工作”的代理与“评判工作”的代理分离,是解决这一问题的一个强有力杠杆。这种分离本身并不会立刻消除宽松倾向;评估器仍然是一个 LLM,而 LLM 天生倾向于对 LLM 生成的输出更宽容。但事实证明,把一个独立评估器调教得更怀疑,远比让生成器批判自己的工作更容易;而一旦这种外部反馈存在,生成器就有了可以据此迭代的具体目标。
前端设计:让主观质量变得可评分
我首先从前端设计开始实验,因为在这里,自我评估问题最为明显。如果不做任何干预,Claude 通常会倾向于安全、可预测的布局:技术上可用,但视觉上平平无奇。
有两个洞见塑造了我为前端设计构建的 harness。第一,虽然审美无法被完全还原为一个分数——而且个人品味永远会有差异——但我们仍然可以通过编码设计原则与偏好的评分标准来提升它。“这个设计美吗?”很难稳定回答,但“它是否遵循了我们的优秀设计原则?”则给了 Claude 一个具体可评分的对象。第二,通过将前端生成与前端评分分离,我们可以建立一个反馈回路,推动生成器朝着更强的输出前进。
基于这一思路,我写了四条评分标准,并将它们同时提供给 generator 和 evaluator 代理作为提示的一部分:
- 设计质量: 设计是否给人一种连贯整体的感觉,而不是零散部件的拼凑?在这一项上表现强,意味着颜色、字体、布局、图像以及其他细节共同营造出鲜明的氛围与身份感。
- 原创性: 是否能看出定制化决策的痕迹,还是只是模板布局、库默认样式和 AI 生成套路?人类设计师应当能识别出有意为之的创意选择。未经修改的现成组件——或者像白卡片上叠紫色渐变这类明显的 AI 生成痕迹——在这里都会失分。
- 工艺: 技术执行层面:字体层级、间距一致性、色彩和谐、对比度比例。这更像是能力检查,而不是创意检查。大多数合理实现默认都能在这里表现不错;如果失败,说明基础功出了问题。
- 功能性: 与审美无关的可用性。用户是否能理解界面做什么、找到主要操作,并在无需猜测的情况下完成任务?
我更强调设计质量和原创性,而不是工艺和功能性。Claude 默认在工艺和功能性上已经得分不错,因为所需的技术能力对模型来说通常是自然具备的。但在设计和原创性方面,Claude 产出的结果往往最多只能算不难看。评分标准明确惩罚高度泛化的“AI 垃圾”模式,而通过提高设计与原创性的权重,也推动模型在审美上承担更多风险。
我使用带有详细分数拆解的 few-shot 示例来校准评估器。这确保了评估器的判断与我的偏好保持一致,也减少了多轮迭代中的评分漂移。
我基于 Claude Agent SDK 构建了这个循环,使编排过程保持简单。首先由一个 generator 代理根据用户提示创建 HTML/CSS/JS 前端。我给 evaluator 配置了 Playwright MCP,使其能够在打分前直接与实时页面交互并检查每一项标准。实际运行中,评估器会自行浏览页面、截图,并仔细研究实现后再给出评估。随后,这些反馈会回流给生成器,作为下一轮迭代的输入。每次生成我会运行 5 到 15 轮迭代,而每一轮通常都会在评估器批评的推动下,把生成器推向更鲜明的方向。由于评估器是在主动浏览页面,而不是对静态截图打分,每个循环都需要真实的墙钟时间。完整运行最长可达四小时。我还要求生成器在每次评估后做出策略性决策:如果分数趋势良好,就继续打磨当前方向;如果方法不奏效,就彻底转向另一种审美风格。
在多次运行中,评估器的评分通常会随着迭代提升,随后进入平台期,而且仍然留有提升空间。有些生成是渐进式优化;另一些则会在迭代之间发生剧烈的审美转向。
评分标准的措辞会以我未完全预料到的方式引导生成器。比如加入“最好的设计应当达到博物馆级别”这样的表述,会把设计推向某种特定的视觉收敛方向,这表明与评分标准相关的提示文本本身,直接塑造了输出的风格特征。
虽然分数通常会随着迭代提高,但这种模式并不总是严格线性的。后期实现整体上往往更好,但我也经常看到自己更喜欢中间某一轮而不是最后一轮的情况。实现复杂度也往往会随着轮次增加而上升,因为生成器会根据评估器的反馈尝试更有野心的方案。即便在第一轮,输出也明显优于完全没有提示的基线,这说明评分标准及其相关语言本身,就已经在任何评估器反馈进一步细化之前,把模型从泛化默认值上拉开了。
有一个特别典型的例子:我让模型为一家荷兰艺术博物馆创建网站。到第九轮时,它生成了一个虚构博物馆的简洁深色主题落地页。页面视觉上很精致,但总体仍在我的预期之内。然后到了第十轮,它彻底推翻了原方案,把网站重新想象成一种空间体验:一个通过 CSS 透视渲染的 3D 房间,带有棋盘地板,艺术作品以自由形式挂在墙上,用户通过门洞在不同展厅之间导航,而不是滚动或点击。这种创造性的飞跃,是我此前从单次生成中从未见过的。
扩展到全栈编码
有了这些发现之后,我将这种受 GAN 启发的模式应用到了全栈开发中。generator-evaluator 循环与软件开发生命周期天然契合,在那里,代码审查和 QA 扮演着与设计评估器相同的结构性角色。
架构
在我们此前的 long-running harness 中,我们已经通过一个 initializer 代理、一个逐个功能推进的 coding 代理,以及会话之间的上下文重置,解决了多会话编码的一致性问题。上下文重置是一个关键突破:那个 harness 使用的是 Sonnet 4.5,而它表现出了前文提到的“上下文焦虑”倾向。构建一个能在上下文重置之间良好运作的 harness,是让模型持续专注于任务的关键。Opus 4.5 基本上自行消除了这种行为,因此我能够在这个 harness 中完全去掉上下文重置。整个构建过程中的代理都在一个连续会话中运行,并由 Claude Agent SDK 的自动压缩机制沿途处理上下文增长。
在这项工作中,我基于原始 harness 的基础,构建了一个三代理系统,每个代理都针对我在先前运行中观察到的特定缺口。系统包含以下代理角色:
Planner: 我们之前的长时运行 harness 需要用户预先提供详细规格。我想把这一步自动化,因此创建了一个 planner 代理,它接收一个 1 到 4 句的简单提示,并将其扩展为完整的产品规格。我提示它在范围上要有野心,同时专注于产品上下文和高层技术设计,而不是详细的技术实现。之所以强调这一点,是因为我担心如果 planner 一开始就试图指定细粒度技术细节并且出错,那么规格中的错误会级联传导到下游实现中。更明智的做法似乎是约束代理需要产出的交付物,让它们在工作过程中自行摸索路径。我还要求 planner 寻找机会,把 AI 功能编织进产品规格中。(示例见文末附录。)
Generator: 早期 harness 中“一次一个功能”的方法在范围管理上效果很好。我在这里采用了类似模型,指示 generator 以 sprint 的方式工作,每次从规格中取一个功能来实现。每个 sprint 都使用 React、Vite、FastAPI 和 SQLite(后来改为 PostgreSQL)技术栈来实现应用,并要求 generator 在每个 sprint 结束时先自我评估,再交给 QA。它还使用 git 做版本控制。
Evaluator: 早期 harness 产出的应用往往看起来很惊艳,但真正使用时仍然存在实际 bug。为了捕捉这些问题,evaluator 使用 Playwright MCP 像用户一样点击运行中的应用,测试 UI 功能、API 端点和数据库状态。然后,它根据自己发现的 bug,以及一组借鉴前端实验并适配到产品深度、功能性、视觉设计和代码质量上的评分标准,对每个 sprint 进行评分。每项标准都有硬性阈值,只要有一项低于阈值,该 sprint 就判定失败,generator 会收到关于问题所在的详细反馈。
在每个 sprint 开始前,generator 和 evaluator 会先协商一个 sprint 合同:在任何代码编写之前,就先约定这一块工作“完成”应当是什么样子。之所以这样做,是因为产品规格本身故意保持高层抽象,而我希望有一个步骤来弥合用户故事与可测试实现之间的差距。generator 提出它将构建什么,以及如何验证成功;evaluator 则审查这份提案,确保 generator 正在构建正确的东西。双方会反复迭代,直到达成一致。
通信通过文件进行:一个代理写文件,另一个代理读取并在该文件中回复,或者写一个新文件供前一个代理继续读取。随后,generator 会依据达成一致的合同进行构建,再把工作交给 QA。这样既能让工作忠实于规格,又不会过早把实现细节规定得过死。
运行 harness
在这个 harness 的第一个版本中,我使用了 Claude Opus 4.5,并将用户提示同时跑在完整 harness 和单代理系统上进行对比。我之所以使用 Opus 4.5,是因为在我开始这些实验时,它是我们最强的编码模型。
我写了下面这个提示来生成一个复古电子游戏制作器:
Create a 2D retro game maker with features including a level editor, sprite editor, entity behaviors, and a playable test mode.
下表展示了 harness 类型、运行时长和总成本。
| Harness | 时长 | 成本 |
|---|---|---|
| Solo | 20 分钟 | $9 |
| Full harness | 6 小时 | $200 |
这个 harness 的成本高出了 20 多倍,但输出质量的差异立刻就显现出来了。
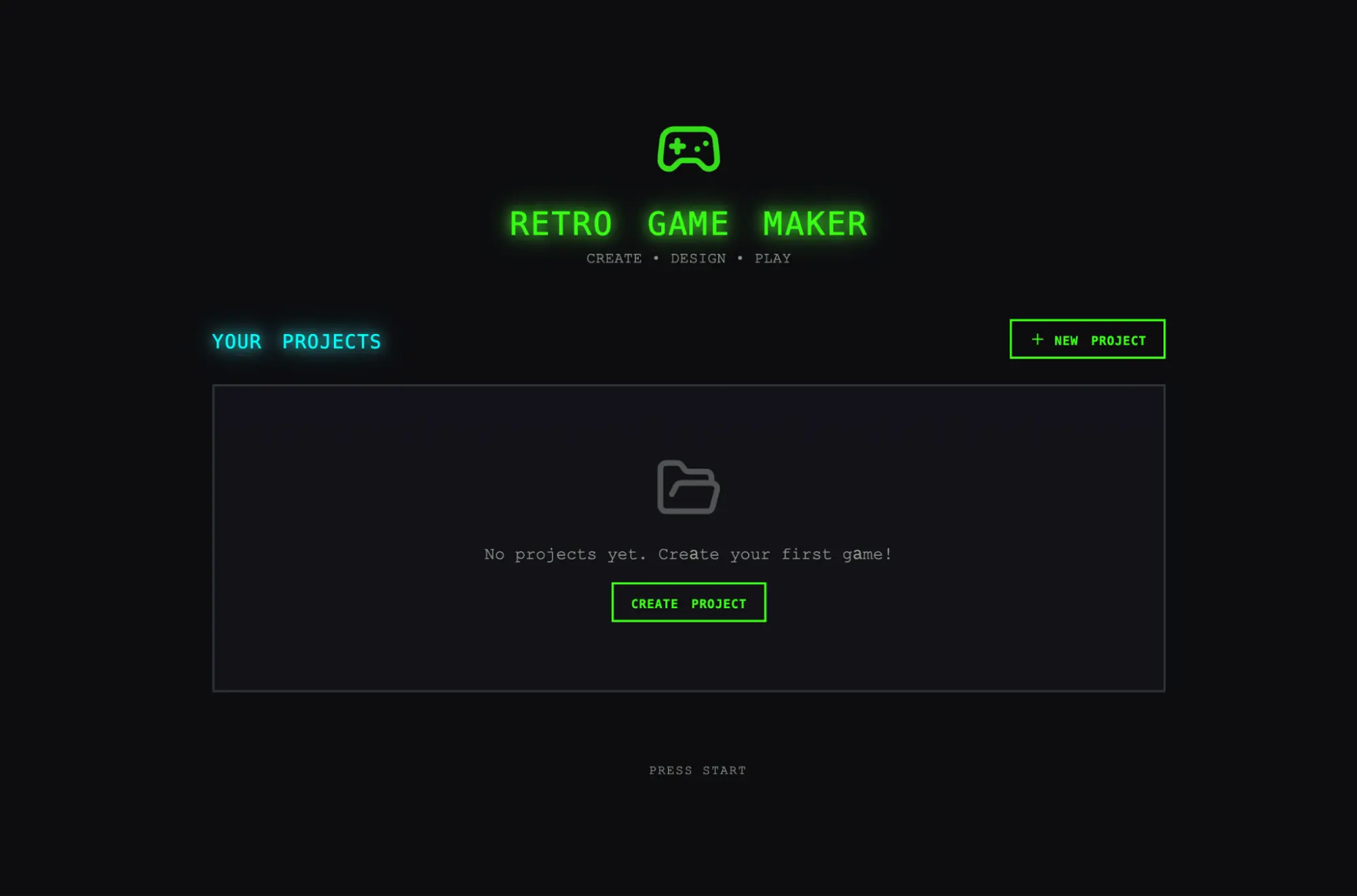
我原本期待的是一个界面:我可以构建关卡及其组成部分(sprites、entities、tile 布局),然后点击播放,真正玩这个关卡。我先打开了 solo 运行的输出,初始应用看起来似乎符合这些预期。
然而,当我开始点击操作时,问题逐渐显现。布局浪费空间,固定高度的面板让大部分视口都空着。工作流也很僵硬。尝试填充关卡时,系统会提示我先创建 sprites 和 entities,但 UI 中没有任何地方引导我遵循这个顺序。更关键的是,实际游戏是坏的。我的 entities 出现在屏幕上,但没有任何东西响应输入。深入查看代码后发现,entity 定义与游戏运行时之间的连接出了问题,而界面上完全看不出问题出在哪里。
打开界面 Sprite 编辑器游戏运行

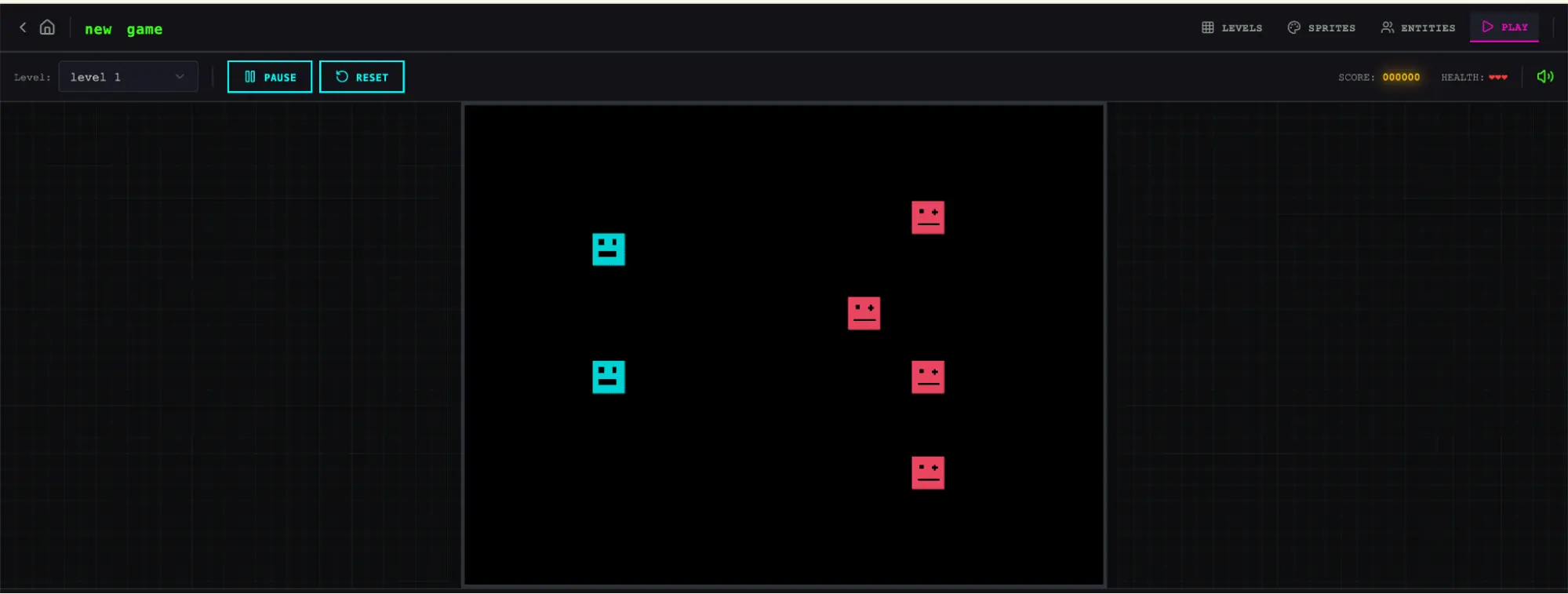
在评估完 solo 运行后,我把注意力转向了 harness 运行。这次运行从同样的一句提示开始,但 planner 步骤将其扩展成了一个包含 16 个功能、分布在十个 sprint 中的规格。它远远超出了 solo 运行尝试的范围。除了核心编辑器和游玩模式之外,规格还要求实现 sprite 动画系统、行为模板、音效与音乐、AI 辅助 sprite 生成器和关卡设计器,以及带可分享链接的游戏导出功能。我让 planner 可以访问我们的 frontend design skill,它读取并利用该技能,为应用创建了一套视觉设计语言,并将其纳入规格之中。对于每个 sprint,generator 和 evaluator 都会协商一份合同,定义该 sprint 的具体实现细节,以及用于验证完成情况的可测试行为。
这个应用立刻就比 solo 运行展现出更多的精致感和流畅度。画布占满了整个视口,面板尺寸合理,界面也拥有一致的视觉识别,与规格中的设计方向保持一致。我在 solo 运行中看到的一些笨拙之处仍然存在——工作流依旧没有明确告诉你,在尝试填充关卡之前应该先构建 sprites 和 entities,我只能通过自己摸索才弄明白。这更像是基础模型在产品直觉上的缺口,而不是 harness 设计本来要解决的问题,不过它也提示了一个方向:如果在 harness 内部做有针对性的迭代,或许还能进一步提升输出质量。
继续使用这些编辑器时,新运行相对于 solo 的优势变得更加明显。sprite 编辑器更丰富、功能更完整,工具面板更整洁,取色器更好用,缩放控制也更实用。
由于我要求 planner 在规格中融入 AI 功能,这个应用还内置了 Claude 集成,让我可以通过提示来生成游戏的不同部分。这显著加快了工作流。
打开界面 Sprite 编辑器AI 游戏设计AI 游戏设计 游戏运行
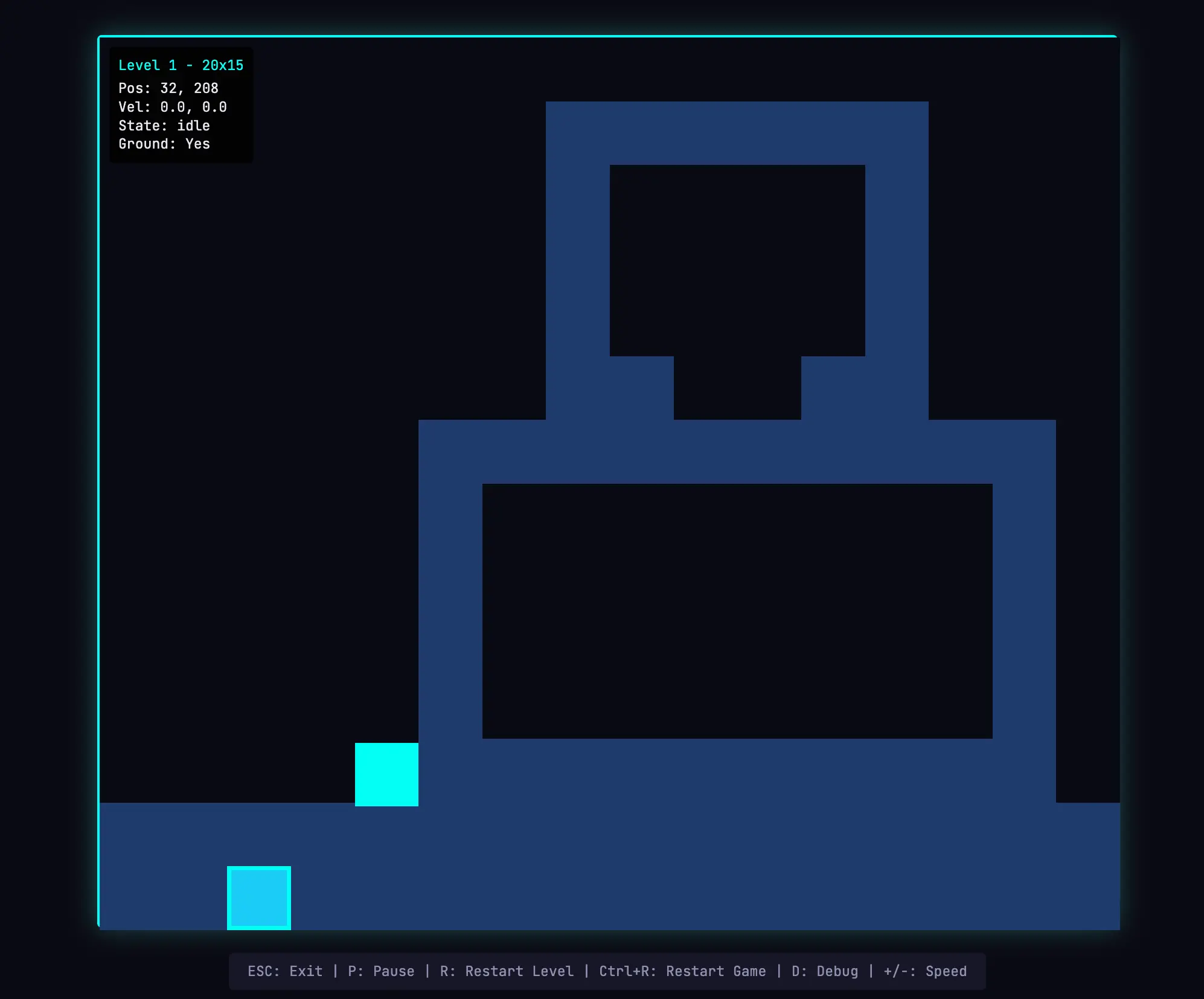
最大的差异体现在游玩模式中。我真的能够移动我的 entity 并玩这个游戏。物理效果还有些粗糙——我的角色跳到平台上后会与平台发生重叠,这在直觉上显得不对——但核心功能是可用的,而 solo 运行并没有做到这一点。稍微移动一会儿之后,我也遇到了 AI 在游戏关卡构建上的一些限制。有一堵很高的墙,我无法跳过去,于是被卡住了。这说明 harness 还可以通过处理一些常识性改进和边缘情况,进一步打磨这个应用。
阅读日志后可以清楚看出,evaluator 让实现始终与规格保持一致。每个 sprint 中,它都会逐条检查 sprint 合同中的测试标准,并通过 Playwright 操作运行中的应用,对任何偏离预期行为的地方提交 bug。合同非常细致——仅 Sprint 3 就有 27 条标准覆盖关卡编辑器——而 evaluator 的发现也足够具体,无需额外调查就能直接采取行动。下表展示了我们的 evaluator 识别出的几个问题示例:
| 合同标准 | 评估器发现 |
|---|---|
| 矩形填充工具允许通过点击拖拽,用所选 tile 填充一个矩形区域 | 失败 — 该工具只会在拖拽起点/终点放置 tile,而不是填满整个区域。fillRectangle 函数存在,但没有在 mouseUp 时被正确触发。 |
| 用户可以选择并删除已放置的实体生成点 | 失败 — LevelEditor.tsx:892 中的 Delete 键处理器要求 selection 和 selectedEntityId 同时被设置,但点击实体时只会设置 selectedEntityId。条件应为 `selection |
| 用户可以通过 API 重新排序动画帧 | 失败 — PUT /frames/reorder 路由定义在 /{frame_id} 路由之后。FastAPI 会把 'reorder' 匹配为一个 frame_id 整数,并返回 422:“unable to parse string as an integer.” |
让 evaluator 达到这种水平并不容易。默认情况下,Claude 并不是一个好的 QA 代理。在早期运行中,我看到它识别出了真实问题,然后又自己说服自己这些问题不算大,最后还是批准了工作。它的测试也倾向于流于表面,而不是深入探查边缘情况,因此更隐蔽的 bug 经常漏掉。调优循环是这样的:阅读 evaluator 的日志,找出它的判断与我不一致的例子,然后更新 QA 的提示来解决这些问题。经过好几轮这样的开发循环后,evaluator 的评分方式才终于达到了我认为合理的程度。即便如此,harness 的输出仍然暴露了模型 QA 能力的边界:一些小的布局问题、某些地方显得不够直观的交互,以及 evaluator 没有充分覆盖到的更深层功能中尚未发现的 bug。显然,通过进一步调优,验证能力仍有不少提升空间。但与 solo 运行相比——后者连应用的核心功能都无法工作——这种提升已经非常明显。
迭代优化 harness
第一批 harness 结果令人鼓舞,但它也显得臃肿、缓慢且昂贵。顺理成章的下一步,就是寻找在不降低性能的前提下简化 harness 的方法。这一方面是常识,另一方面也体现了一个更普遍的原则:harness 中的每个组件都编码了一种关于“模型自身做不到什么”的假设,而这些假设值得被压力测试——既因为它们可能本来就是错的,也因为随着模型进步,它们会很快过时。我们的博文 Building Effective Agents 将这一底层思想概括为“找到尽可能简单的解决方案,只有在必要时才增加复杂度”,而这也是任何维护代理 harness 的人都会反复遇到的模式。
在我第一次尝试简化时,我大幅削减了 harness,并尝试了一些新的创意想法,但没能复现原始版本的性能。与此同时,也越来越难判断 harness 设计中的哪些部分是真正承重的,以及它们究竟以什么方式承重。基于这次经验,我转向了更系统的方法:一次只移除一个组件,然后观察它对最终结果的影响。
在我经历这些迭代周期的同时,我们也发布了 Opus 4.6,这进一步增强了我降低 harness 复杂度的动机。有充分理由预期,4.6 所需的脚手架会比 4.5 更少。正如我们在发布博文中所说:“[Opus 4.6] 规划更谨慎,能更长时间维持代理式任务,在更大的代码库中运行得更可靠,并且具备更好的代码审查和调试能力来发现自己的错误。”它在长上下文检索方面也有了显著提升。这些能力,原本都是 harness 用来补足的。
去掉 sprint 结构
我首先尝试彻底移除 sprint 结构。sprint 结构原本有助于把工作拆成小块,让模型能够连贯地处理。考虑到 Opus 4.6 的改进,有充分理由相信模型可以原生处理这项工作,而不再需要这种拆解。
我保留了 planner 和 evaluator,因为它们各自仍然带来明显价值。没有 planner 时,generator 会低估范围:面对原始提示,它会直接开始构建,而不会先为自己的工作制定规格,最终产出的应用功能丰富度不如 planner 生成的版本。
在移除 sprint 结构后,我把 evaluator 改成在运行结束时做一次单次评估,而不是按 sprint 逐轮打分。由于模型能力更强了,evaluator 对某些运行而言的“承重性”也发生了变化,它的价值取决于任务相对于模型自身可靠能力边界所处的位置。在 4.5 上,这个边界很近:我们的构建任务正处于 generator 单独完成能力的边缘,而 evaluator 能在整个构建过程中捕捉到有意义的问题。在 4.6 上,模型的原始能力提升了,因此边界向外移动。那些过去需要 evaluator 检查才能连贯实现的任务,现在往往已经落入 generator 自己就能处理好的范围;对于处于这个边界之内的任务,evaluator 就成了不必要的额外开销。但对于那些仍然处于 generator 能力边缘的构建部分,evaluator 依然能带来真实提升。
实际含义是,evaluator 不是一个固定的“要不要”的二元决策。当任务超出当前模型单独可靠完成的范围时,它就值得这笔成本。
在结构简化的同时,我还增加了提示,以改进 harness 将 AI 功能构建进每个应用的方式,具体来说,就是让 generator 构建一个真正的代理,能够通过工具驱动应用自身的功能。这需要实打实的迭代,因为相关知识足够新,Claude 的训练数据对此覆盖还比较薄弱。但经过足够多的调优后,generator 已经能够正确构建代理。
更新后 harness 的结果
为了测试更新后的 harness,我使用了下面这个提示来生成一个数字音频工作站(DAW),也就是用于作曲、录音和混音的音乐制作程序:
Build a fully featured DAW in the browser using the Web Audio API.
这次运行依然很长、也很昂贵,大约耗时 4 小时,token 成本为 124 美元。
大部分时间都花在 builder 上;在没有 Opus 4.5 所需的 sprint 拆解的情况下,它仍然连贯地运行了两个多小时。
| 代理与阶段 | 时长 | 成本 |
|---|---|---|
| Planner | 4.7 分钟 | $0.46 |
| Build(第 1 轮) | 2 小时 7 分钟 | $71.08 |
| QA(第 1 轮) | 8.8 分钟 | $3.24 |
| Build(第 2 轮) | 1 小时 2 分钟 | $36.89 |
| QA(第 2 轮) | 6.8 分钟 | $3.09 |
| Build(第 3 轮) | 10.9 分钟 | $5.88 |
| QA(第 3 轮) | 9.6 分钟 | $4.06 |
| V2 Harness 总计 | 3 小时 50 分钟 | $124.70 |
和之前的 harness 一样,planner 将这一行提示扩展成了完整规格。从日志中我可以看到,generator 模型在规划应用和代理设计、连接代理以及在交给 QA 之前进行测试方面都做得很好。
不过,QA 代理仍然捕捉到了真实缺口。在第一轮反馈中,它指出:
这是一个很强的应用,设计还原度很高,AI 代理扎实,后端也不错。主要失败点在于功能完整性——虽然应用看起来很惊艳,AI 集成也运作良好,但几个核心 DAW 功能只有展示,没有足够的交互深度:片段无法在时间线上拖拽/移动,没有乐器 UI 面板(如合成器旋钮、鼓垫),也没有可视化效果编辑器(如 EQ 曲线、压缩器表头)。这些不是边缘情况——它们是让 DAW 真正可用的核心交互,而规格中也明确要求了它们。
在第二轮反馈中,它再次发现了几个功能缺口:
剩余缺口:
- 音频录制仍然只是桩实现(按钮会切换,但没有麦克风采集)
- 尚未实现通过边缘拖拽调整片段大小,以及片段切分
- 效果可视化仍是数字滑块,而不是图形化界面(没有 EQ 曲线)
如果任由 generator 自行发挥,它仍然容易漏掉细节或把某些功能做成桩实现,而 QA 在捕捉这些“最后一公里”问题、让 generator 去修复方面依然有价值。
根据这个提示,我原本期待的是一个程序:我可以在其中创建旋律、和声和鼓点模式,把它们编排成一首歌,并在过程中得到一个集成代理的帮助。下面的视频展示了结果。
这个应用距离专业音乐制作程序还很远,代理在歌曲创作上的能力显然也还有很多提升空间。此外,Claude 实际上并不能“听”,这使得 QA 反馈循环在音乐审美方面的效果打了折扣。
但最终的应用已经具备了一个可用音乐制作程序的所有核心部件:浏览器中可运行的编排视图、混音器和传输控制。除此之外,我还能够完全通过提示拼出一段简短的歌曲片段:代理设置了速度和调性,铺好了旋律,构建了鼓轨,调整了混音器电平,并添加了混响。歌曲创作所需的核心原语都已经具备,而代理也能自主驱动它们,借助工具从头到尾完成一个简单制作。你也许会说它现在还谈不上“音准完美”——但它正在接近。
接下来会怎样
随着模型持续进步,我们大致可以预期,它们将能够工作更久,并处理更复杂的任务。在某些情况下,这意味着围绕模型搭建的脚手架会随着时间推移变得不那么重要,开发者只需等待下一代模型,就能看到某些问题自行消失。另一方面,模型越强,也就越有空间去开发 harness,使其能够完成那些超出模型基线能力的复杂任务。
基于这一点,这项工作中有几条经验值得延续。针对你所依赖的模型做实验、阅读它在真实问题上的轨迹,并调优其表现以达到你想要的结果,始终是好做法。在处理更复杂任务时,通过拆解任务并为问题的各个方面配置专门代理,有时确实能挖掘出额外空间。而当一个新模型发布时,通常也应该重新审视现有 harness:去掉那些对性能已不再承重的部分,同时加入新的部分,以实现此前无法达到的更强能力。
通过这项工作,我愈发确信:随着模型进步,有趣的 harness 组合空间并不会缩小。相反,它会移动,而 AI 工程师真正有趣的工作,就是不断找到下一个新颖的组合。
致谢
特别感谢 Mike Krieger、Michael Agaby、Justin Young、Jeremy Hadfield、David Hershey、Julius Tarng、Xiaoyi Zhang、Barry Zhang、Orowa Sidker、Michael Tingley、Ibrahim Madha、Martina Long 和 Canyon Robbins 对这项工作的贡献。
也感谢 Jake Eaton、Alyssa Leonard 和 Stef Sequeira 在本文成稿过程中提供的帮助。
附录
由 planner 代理生成的示例计划。
RetroForge - 2D 复古游戏制作器
概述
RetroForge 是一个基于 Web 的创意工作室,用于设计和构建 2D 复古风格电子游戏。它将经典 8 位和 16 位游戏美学所带来的怀旧魅力,与现代、直观的编辑工具结合起来——让从业余创作者到独立开发者的任何人,都能在无需编写传统代码的情况下,将自己的游戏创意变为现实。
该平台提供四个集成式创作模块:用于设计游戏世界的基于 tile 的关卡编辑器、用于制作视觉资产的像素风 Sprite 编辑器、用于定义游戏逻辑的可视化实体行为系统,以及用于实时游戏测试的即时可玩测试模式。通过将 AI 辅助贯穿整个流程(由 Claude 提供支持),RetroForge 加速了创作过程——帮助用户通过自然语言交互生成 sprites、设计关卡并配置行为。
RetroForge 面向热爱复古游戏美学、但又希望拥有现代便利性的创作者。无论是重现童年时代的平台跳跃、RPG 或动作游戏,还是在复古约束下发明全新的体验,用户都可以快速制作原型、以可视化方式迭代,并与他人分享自己的作品。
功能
1. 项目仪表盘与管理
项目仪表盘是 RetroForge 中所有创作工作的主入口。用户需要一种清晰、有组织的方式来管理他们的游戏项目——创建新项目、返回进行中的作品,并一眼了解每个项目包含什么。
用户故事:作为用户,我希望能够:
- 创建一个带有名称和描述的新游戏项目,以便开始设计我的游戏
- 以可视化卡片形式查看我所有现有项目,卡片展示项目名称、最后修改日期和缩略图预览,以便我能快速找到并继续我的工作
- 打开任意项目,进入完整的游戏编辑器工作区,以便我能继续开发我的游戏
- 删除我不再需要的项目,并带有确认对话框以防误操作,从而保持工作区整洁有序
- 复制一个现有项目作为新游戏的起点,以便复用我之前的工作
项目数据模型:每个项目包含:
项目元数据(名称、描述、创建/修改时间戳)
画布设置(分辨率:例如 256x224、320x240 或 160x144)
Tile 尺寸配置(8x8、16x16 或 32x32 像素)
调色板选择
所有关联的 sprites、tilesets、levels 和实体定义
...
复制
获取开发者新闻通讯
产品更新、操作指南、社区精选等更多内容。每月发送到你的收件箱。
如果你希望接收我们的每月开发者新闻通讯,请提供你的电子邮箱地址。你可以随时取消订阅。