扩展托管代理:将大脑与双手解耦
随着模型不断改进,harness 中编码的假设会逐渐过时。Managed Agents——我们面向长周期代理任务的托管服务——围绕一组稳定接口构建,即使 harness 发生变化,这些接口依然保持稳定。
按照我们的文档开始使用 Claude Managed Agents。
工程博客中的一个持续话题是如何构建高效代理,以及如何为长时间运行的工作设计 harness。这些工作的一个共同主线是:harness 编码了关于 Claude 无法独立完成哪些事情的假设。然而,这些假设需要被频繁重新审视,因为随着模型能力提升,它们可能会逐渐失效。
仅举一个例子,在此前的工作中,我们发现 Claude Sonnet 4.5 在感知到上下文窗口即将达到上限时,会过早结束任务——这种行为有时被称为“上下文焦虑(context anxiety)”。我们通过在 harness 中加入上下文重置来解决这个问题。但当我们将同样的 harness 用在 Claude Opus 4.5 上时,发现这种行为已经消失了。那些重置逻辑反而成了累赘。
我们预计 harness 还会继续演进。因此我们构建了 Managed Agents:这是 Claude Platform 中的一项托管服务,通过一小组接口代表你运行长周期代理,而这些接口的设计目标是比任何具体实现都更持久——包括我们今天正在运行的实现。
构建 Managed Agents 意味着要解决计算领域中的一个老问题:如何为“尚未被想到的程序”设计系统。几十年前,操作系统通过将硬件虚拟化为抽象——进程、文件——来解决这个问题,这些抽象足够通用,能够支持当时尚不存在的程序。这些抽象比硬件本身更长寿。read() 命令并不关心它访问的是 1970 年代的磁盘组,还是现代 SSD。上层抽象保持稳定,而底层实现则可以自由变化。
Managed Agents 遵循同样的模式。我们将代理的组成部分虚拟化了:session(记录所有发生事件的只追加日志)、harness(调用 Claude 并将 Claude 的工具调用路由到相关基础设施的循环),以及 sandbox(Claude 可在其中运行代码和编辑文件的执行环境)。这使得每个部分的实现都可以在不影响其他部分的情况下被替换。我们对这些接口的形态有明确主张,但并不限定其背后运行的具体实现。
不要养“宠物”
我们一开始将所有代理组件都放进一个容器中,这意味着 session、agent harness 和 sandbox 共享同一个环境。这种做法有一些好处,比如文件编辑是直接系统调用,也不需要设计服务边界。
但由于把所有东西都耦合进一个容器,我们遇到了一个老牌基础设施问题:我们养了一只宠物。在“宠物 vs 牲畜”的类比中,宠物是有名字、需要人工照料、不能承受失去的个体;而牲畜则是可互换的。在我们的场景里,服务器就成了那只宠物;如果某个容器失败,session 就会丢失。如果某个容器没有响应,我们就不得不想办法把它“救活”。
“照料”这些容器意味着要调试那些卡住且无响应的 session。我们唯一能看到的窗口是 WebSocket 事件流,但它无法告诉我们故障究竟发生在哪里,这意味着 harness 中的 bug、事件流中的丢包,或容器离线,表现出来都一样。为了弄清楚到底出了什么问题,工程师必须进入容器内部打开 shell;但由于那个容器通常也保存着用户数据,这种做法实际上意味着我们缺乏可行的调试能力。
第二个问题是,harness 假设 Claude 所处理的内容就和它自己一起存在于容器中。当客户要求我们将 Claude 连接到他们的虚拟私有云时,他们要么必须将自己的网络与我们的网络打通,要么必须在自己的环境中运行我们的 harness。一个被写死在 harness 中的假设,在我们想把它连接到不同基础设施时,就变成了问题。
将大脑与双手解耦
我们最终采用的解决方案,是将我们所认为的“大脑”(Claude 及其 harness)与“双手”(执行动作的 sandbox 和工具)以及“session”(session 事件日志)解耦。每一部分都变成了一个对其他部分假设极少的接口,并且每一部分都可以独立失败或被替换。
harness 离开容器。 将大脑与双手解耦,意味着 harness 不再驻留在容器内部。它像调用其他任何工具一样调用容器:execute(name, input) → string。容器因此变成了“牲畜”。如果容器宕掉,harness 会将该失败捕获为一次工具调用错误,并将其返回给 Claude。如果 Claude 决定重试,就可以用一个标准配方重新初始化一个新容器:provision({resources})。我们不再需要费力去“救活”失败的容器。
从 harness 故障中恢复。 harness 本身也变成了“牲畜”。由于 session 日志位于 harness 之外,harness 中没有任何东西必须在崩溃后幸存。当某个 harness 失败时,可以通过 wake(sessionId) 启动一个新的实例,使用 getSession(id) 取回事件日志,并从最后一个事件继续恢复。在代理循环期间,harness 通过 emitEvent(id, event) 将事件写入 session,以保留一份持久的事件记录。

安全边界。 在耦合式设计中,Claude 生成的任何不受信任代码,都会与凭证一起运行在同一个容器中——因此一次提示注入只需要说服 Claude 去读取它自己的环境即可。一旦攻击者拿到这些令牌,他们就可以启动新的、不受限制的 session,并把工作委派给它们。缩小权限范围显然是一种缓解方式,但这实际上编码了一个关于 Claude 在拿到受限令牌后“做不到什么”的假设——而 Claude 正变得越来越聪明。结构性的修复方式,是确保这些令牌永远无法从 Claude 生成代码所运行的 sandbox 中被访问到。
我们使用了两种模式来确保这一点。认证信息可以与资源绑定,也可以保存在 sandbox 之外的保险库中。对于 Git,我们在 sandbox 初始化期间使用每个仓库的访问令牌来克隆仓库,并将其接入本地 git remote。这样,Git push 和 pull 可以在 sandbox 内部工作,而代理本身从未接触过令牌。对于自定义工具,我们支持 MCP,并将 OAuth 令牌存储在安全保险库中。Claude 通过专用代理调用 MCP 工具;该代理接收一个与 session 关联的令牌。随后,代理可以从保险库中取出对应凭证,并向外部服务发起调用。harness 永远不会接触任何凭证。
session 不是 Claude 的上下文窗口
长周期任务往往会超出 Claude 上下文窗口的长度,而解决这一问题的标准方法都涉及对“保留什么”做出不可逆的决定。我们在此前关于上下文工程的工作中探讨过这些技术。例如,压缩(compaction)允许 Claude 保存其上下文窗口的摘要,而 memory 工具允许 Claude 将上下文写入文件,从而实现跨 session 学习。这还可以与上下文裁剪(context trimming)配合使用,有选择地移除旧工具结果或 thinking 块等 token。
但这种有选择地保留或丢弃上下文的不可逆决策,可能会导致失败。因为很难知道未来的轮次究竟需要哪些 token。如果消息经过压缩步骤转换,harness 会将被压缩的消息从 Claude 的上下文窗口中移除,而这些内容只有在被存储的情况下才能恢复。此前的工作已经探索了通过将上下文存储为一个存在于上下文窗口之外的对象来解决这一问题的方法。例如,上下文可以是 REPL 中的一个对象,LLM 通过编写代码以编程方式访问它,对其进行过滤或切片。
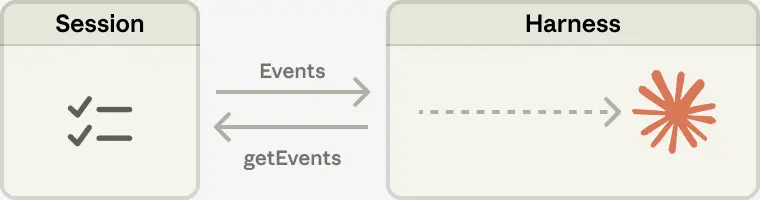
在 Managed Agents 中,session 提供了同样的好处,充当一个存在于 Claude 上下文窗口之外的上下文对象。但它不是存储在 sandbox 或 REPL 中,而是被持久地存储在 session 日志里。接口 getEvents(), 允许大脑通过选择事件流中的位置切片来查询上下文。这个接口可以被灵活使用,使大脑能够从上次停止读取的位置继续,回退到某个特定时刻之前的几个事件以查看前因后果,或在某个特定动作之前重新读取上下文。
任何获取到的事件,也都可以在传入 Claude 的上下文窗口之前先在 harness 中进行转换。这些转换可以是 harness 所编码的任何内容,包括为了获得较高 prompt cache 命中率而进行的上下文组织,以及上下文工程。我们将 session 中可恢复的上下文存储,与 harness 中任意的上下文管理这两个关注点分离开来,因为我们无法预测未来模型究竟需要什么样的具体上下文工程。这些接口将上下文管理推给 harness,只保证 session 是持久的,并且可供查询。
多个大脑,多双手
多个大脑。 将大脑与双手解耦,解决了我们最早收到的客户抱怨之一。当团队希望 Claude 访问他们自己 VPC 中的资源时,唯一的路径是将他们的网络与我们的网络打通,因为承载 harness 的容器假设所有资源都在它旁边。一旦 harness 不再位于容器中,这个假设就消失了。同样的改变还带来了性能收益。当我们最初把大脑放进容器时,这意味着有多少个大脑,就需要多少个容器。对于每个大脑,在该容器完成配置之前都无法进行推理;每个 session 一开始都要承担完整的容器启动成本。每个 session——即便那些永远不会接触 sandbox 的 session——都必须克隆仓库、启动进程、从我们的服务器拉取待处理事件。
这段空转时间体现在首个 token 时间(TTFT)上,它衡量的是一个 session 从接受工作到产出第一个响应 token 之间等待了多久。TTFT 是用户感受最直接、最明显的延迟。
将大脑与双手解耦意味着,只有在确实需要时,容器才会由大脑通过一次工具调用 (execute(name, input) → string) 来配置。因此,一个不需要立即使用容器的 session 就无需为容器等待。只要编排层从 session 日志中拉取到待处理事件,推理就可以开始。使用这种架构后,我们的 p50 TTFT 大约下降了 60%,p95 则下降了超过 90%。扩展到多个大脑,只意味着启动多个无状态 harness,并且仅在需要时将它们连接到双手。
多双手。 我们还希望能够将每个大脑连接到多双手。在实践中,这意味着 Claude 必须对多个执行环境进行推理,并决定将工作发送到哪里——这比在单一 shell 中操作是更困难的认知任务。我们一开始将大脑放在单个容器中,是因为更早期的模型还不具备这种能力。随着智能水平提升,单容器反而成了限制:一旦那个容器失败,我们就会丢失大脑所伸向每一双手的状态。
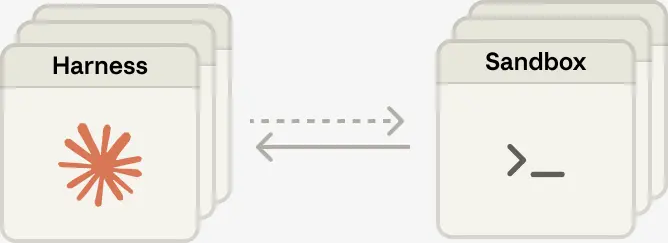
将大脑与双手解耦,使每一双手都成为一个工具,execute(name, input) → string:输入一个名称和参数,返回一个字符串。这个接口支持任何自定义工具、任何 MCP 服务器,以及我们自己的工具。harness 不需要知道 sandbox 是一个容器、一部手机,还是一个宝可梦模拟器。而且由于没有任何一双手与任何一个大脑耦合,大脑之间还可以彼此传递双手。
结论
我们所面对的挑战是一个老问题:如何为“尚未被想到的程序”设计系统。操作系统之所以能延续数十年,是因为它们将硬件虚拟化为足够通用的抽象,从而能够支持当时尚不存在的程序。借助 Managed Agents,我们的目标是设计一个能够容纳围绕 Claude 的未来 harness、sandbox 或其他组件的系统。
Managed Agents 也是一种同样精神下的 meta-harness,它并不对 Claude 未来将需要的具体 harness 预设立场。相反,它是一个拥有通用接口的系统,允许许多不同的 harness 存在。例如,Claude Code 就是一个优秀的 harness,我们已在各种任务中广泛使用它。我们也已经证明,面向特定任务的 agent harness 在狭窄领域中表现出色。Managed Agents 可以容纳这些任意一种,并随着时间推移匹配 Claude 的智能水平。
meta-harness 设计意味着,我们对 Claude 周围的接口有明确主张:我们预计 Claude 需要操纵状态的能力(session)以及执行计算的能力(sandbox)。我们也预计 Claude 需要扩展到多个大脑和多双手的能力。我们设计这些接口,是为了让这些能力能够在长时间跨度上可靠且安全地运行。但我们并不对 Claude 将需要多少个大脑或双手、它们位于何处做任何假设。
致谢
本文由 Lance Martin、Gabe Cemaj 和 Michael Cohen 撰写。感谢 Nodir Turakulov 和 Jeremy Fox 就这些主题进行的有益交流。特别感谢 Agents API 团队和 Jake Eaton 的贡献。
获取开发者新闻通讯
产品更新、操作指南、社区聚焦等更多内容。每月发送到你的收件箱。
如果你希望接收我们的每月开发者新闻通讯,请提供你的电子邮箱地址。你可以随时取消订阅。